排查过程
线上一台服务器从周一下午开始告警,告警内容为“Full GC比较频繁”。一开始大家都没有在意,猜想可能是部分业务压力有点大了,等高峰期过了就好了。
然而告警邮件的提醒一直响到了第二天。
周二中午,脆骨首先开始了排查,登录跳板机后,通过jstat工具查看GC情况,发现该应用的老年代占用100%,大约每5秒触发一次Full GC,但Full GC后没有效果,老年代占用依然为100%,据此我们推测应该是有大量业务对象滞留在了内存中。我们开始第一次尝试使用jmap来dump堆,以期通过分析堆中的对象来定位问题,然而第一次仅dump出18M的内容,分析后没有发现有价值的内容,考虑到老年代长期占用100%已经使得该应用无法正确响应线上请求了,我们重启了该应用,观察启动后的GC情况是正常的。
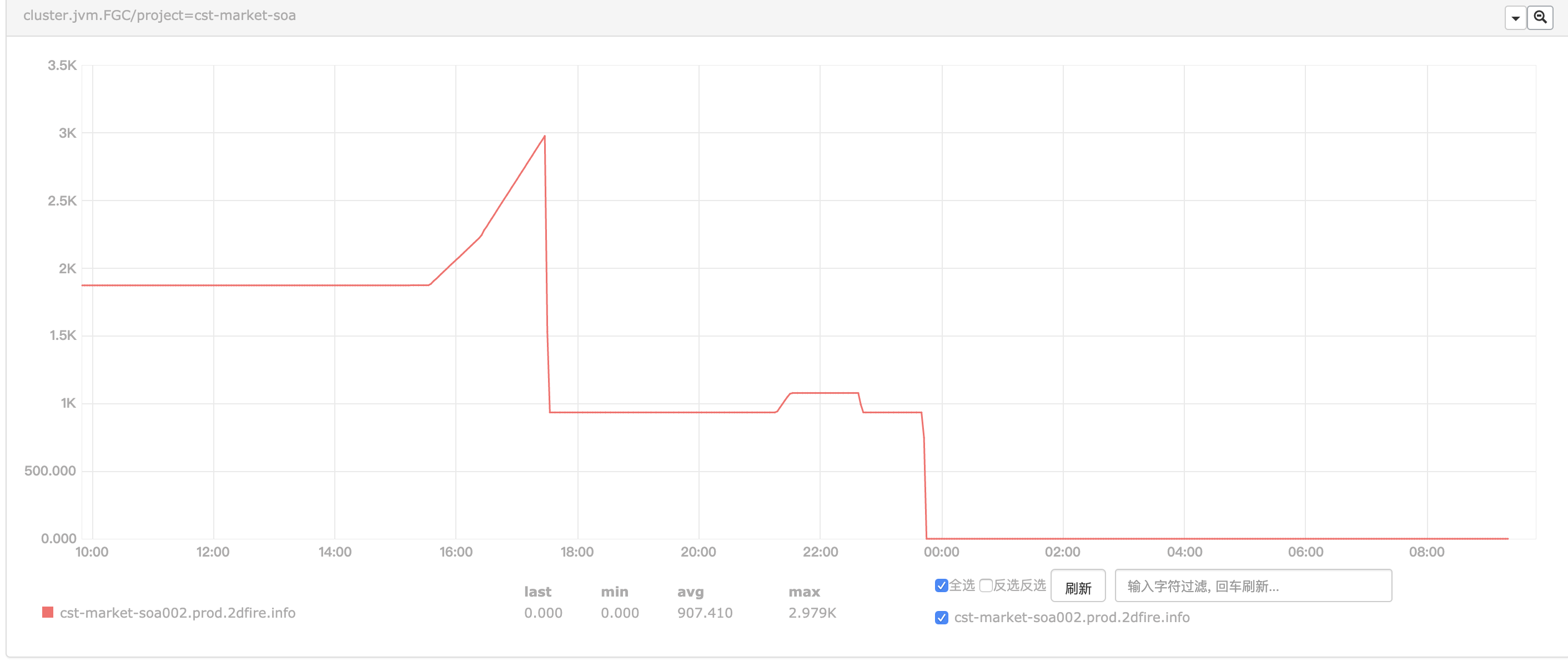
周二晚上下班后,我和脆骨再次登录服务器排查该问题。21时11分,应用日志显示有一家店启动了某一类型的活动,接下来的几分钟里,应用的老年代占用率迅速上升,并导致开始频繁Full GC,告警邮件也再次出现。到此我们初步确定了问题是由该类型的活动导致的,并第二次使用jmap将堆dump出来进行分析,这次成功dump出4.3G的hprof文件。

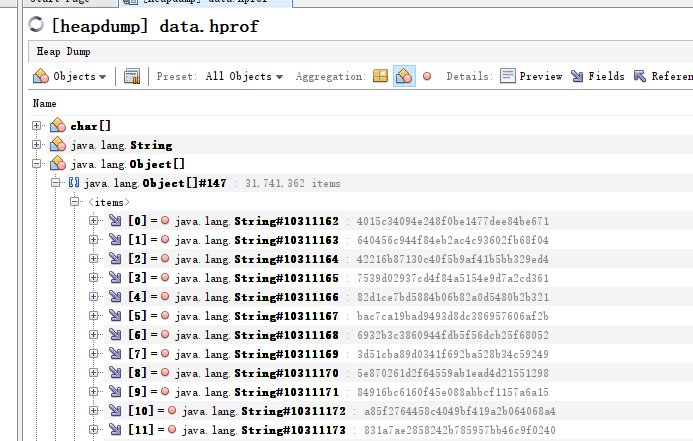
在将dump出的hprof文件载入visualvm中之后,发现char数组占用了51.4%的堆空间,进一步分析发现有一个ArrayList存储了3174万个字符串,内容均为会员id。通过分析代码,我们发现有一段逻辑是需要从数据库中查询之前该活动已参与的对象,为了减轻数据库压力,开发通过循环分页查询来一页页地将数据查询出来,直到查询不到数据时跳出循环。在查询数据的代码中,我们发现周一有过一次代码变更,修改了传入查询语句的分页参数,更加深入地分析代码后,我们发现变更的分页参数并未赋值,其实际值总是为0,导致每次查询都是查第一页的数据,无法跳出循环,查询的结果又被缓存到一个ArrayList中,这才导致了老年代被填满,不断触发Full GC。
在调整了查询数据的代码后,老年代占用恢复正常,Full GC也不再频繁出现。
经验总结
- 关键操作一定要充分单测;
- 循环跳出条件如果依赖于数据库查询,对查询的语句和各个参数必须做到心中有数;
- 流程测试,对每个流程将要出现的结果要有预期,并在测试完成后将实际结果与预期结果进行比对;
- 线上告警要重视,对于应用的运行指标出现的异常要敏感,尽早定位问题,解决问题。